Oglas
Vjerujete li u ideju da nakon što se nešto objavi na internetu to zauvijek objavi? Pa, danas ćemo taj mit rastjerati.
Istina je da je u mnogim slučajevima moguće iskorijeniti podatke s Interneta. Sigurno, postoji zapis web stranica koje su izbrisane ako pretražite Wayback strojzar ne? Da, apsolutno. Na uređaju Wayback možete pronaći zapise web stranica koje se vraćaju dugi niz godina - stranice koje nećete pronaći Google pretraživanjem, jer web stranica više ne postoji. Netko ga je izbrisao ili je web mjesto zatvoreno.
Dakle, ne možemo to zaobići, zar ne? Informacije će se zauvijek ugraditi u kamen Interneta, tamo kako bi ga generacije mogle vidjeti? Pa, ne baš.
Istina je da, iako može biti teško ili nemoguće izbrisati glavne vijesti koje su se proširile s jedne vijesti ili bloga na drugu poput virusa, zapravo je prilično lako izbrisati web stranicu ili nekoliko web stranica iz svih zapisa o postojanju - ukloniti tu stranicu s obje tražilice i Wayback stroj Novi povratni stroj omogućuje vizualno putovanje natrag u internetsko vrijeme Čini se da su od pokretanja Wayback Machine 2001. godine vlasnici web mjesta odlučili izbaciti back-end sa sjedištem u Alexa i redizajnirati ga vlastitim otvorenim kodom. Nakon provođenja ispitivanja s ... Čitaj više . Naravno, postoji ulov, ali doći ćemo do toga.
3 načina za uklanjanje stranica bloga s Interneta
Prva metoda je ona koju koristi većina vlasnika web mjesta, jer oni ne znaju bolje - jednostavno brisanje web stranica. To se može dogoditi zato što ste shvatili da na vašem web mjestu imate duplikat sadržaja ili imate stranicu koju ne želite prikazivati u rezultatima pretraživanja.
Jednostavno izbrišite stranicu
Problem s potpuno brisanjem stranica s vaše web stranice je u tome što ste je već postavili na stranici Neto, vjerojatno postoje veze s vaše vlastite stranice kao i vanjske veze s drugih web mjesta na tu određenu stranica. Kad ga izbrišete, Google će odmah prepoznati vašu stranicu kao stranicu koja nedostaje.
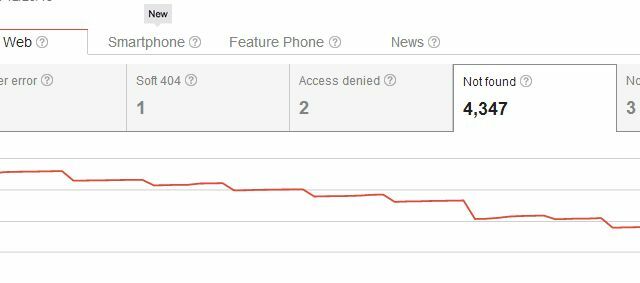
Dakle, brisanjem stranice ne samo da ste stvorili problem s pogreškama u pretraživanju "Nije pronađen", već ste stvorili problem svima koji su ikada povezali stranicu. Korisnici koji na vašu web lokaciju stignu s jedne od tih vanjskih veza vidjet će vašu stranicu 404, što nije glavni je problem ako koristite nešto poput Googleovog prilagođenog koda 404 da biste korisnicima dali korisne prijedloge ili alternative. Ali mislite da bi mogli postojati elegantniji načini brisanja stranica iz rezultata pretraživanja, a da pritom ne otkrijete sve one 404 za postojeće dolazne veze, zar ne?
Pa, postoje.
Uklonite stranicu iz rezultata Google pretraživanja
Prije svega, trebali biste razumjeti da ako web-stranica koju želite ukloniti iz rezultata Google pretraživanja nije stranica s vaše vlastite web lokacije, onda nemate sreće, osim ako nema zakonskih razloga ili ako je web stranica objavila vaše osobne podatke na mreži bez vaših dopuštenje. Ako je to slučaj, koristite Googleove uklanjanje problema s uklanjanjem podnijeti zahtjev za uklanjanje stranice iz rezultata pretraživanja. Ako imate valjan slučaj, možda ćete pronaći uspjeh s uklanjanjem stranice - naravno možda ćete imati još veći uspjeh kontaktiranje vlasnika web mjesta Kako ukloniti lažne osobne podatke na InternetuPrivatnost na mreži više nije zajamčena. Saznajte kako prijaviti web mjesto i ukloniti osobne podatke s interneta. Čitaj više kao što sam opisao kako to učiniti 2009. godine.
Ako se stranica koju želite ukloniti iz rezultata pretraživanja nalazi na vašoj web lokaciji, imate sreće. Sve što trebate učiniti je stvoriti robots.txt datoteku i provjerite jeste li onemogućili određenu stranicu koju ne želite u rezultatima pretraživanja, ili cijeli direktorij sa sadržajem koji ne želite indeksirati. Evo kako izgleda blokiranje jedne stranice.
Korisnički agent: * Onemogući: /my-deleted-article-that-i-want-removed.html
Možete blokirati botove da pretražuju cijele direktorije vaše web stranice kako slijedi.
Korisnički agent: * Onemogući: / sadržaj-o-osobnim stvarima /
Google je odličan stranicu za podršku što vam može pomoći stvoriti datoteku robots.txt ako je nikad niste stvorili. To djeluje izuzetno dobro, kao što sam objasnio nedavno u članku o strukturiranje sindikalnih poslova Kako pregovarati o ponudama za udruživanje i zaštititi svoje liste pretraživanjaUdruživanje je ovih dana bijes. Ali odjednom ste mogli utvrditi da je udruženi partner u rezultatima pretraživanja naveden viši od vas u rezultatima pretraživanja za priču koju ste napisali! Zaštitite svoje ljestvice pretraživanja. Čitaj više tako da vas ne povrijede (zamolite partnere za udruživanje da onemoguće indeksiranje stranica na kojima ste udruženi). Jednom kada je moj vlastiti partner za udruživanje pristao na to, stranice koje su duplicirane od sadržaja s mog bloga potpuno su nestale s popisa za pretraživanje.
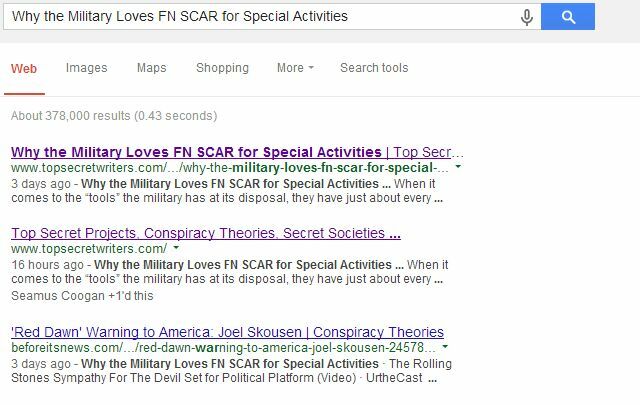
Na glavnom mjestu nalazi se samo glavna web stranica na kojoj se nalazi naš naslov, ali moj je blog sada naveden i na prvom i na drugom mjestu; nešto što bi bilo gotovo nemoguće da web stranica višeg autoriteta dupliciranu stranicu ostavi indeksiranu.
Ono što mnogi ne shvaćaju jest da je to moguće postići i s internetskom arhivom (Wayback Machine). Evo redaka koje trebate dodati u svoju datoteku robots.txt da biste je ostvarili.
Korisnički agent: ia_archiver. Zaustavi: / uzorak-kategorija /
U ovom primjeru kažem internetskoj arhivi da ukloni bilo što u poddirektoriju kategorije uzorka na svojoj web lokaciji s Wayback Machine. Internet arhiva objašnjava kako to učiniti na njihovoj stranici pomoći za izuzimanje. Tu objašnjavaju i da "Internet Arhiva nije zainteresirana za pristup web stranicama ili drugim internetskim dokumentima čiji autori ne žele svoje materijale u zbirci."
To je suprotno uvriježenom mišljenju da bilo što objavljeno na Internetu bude uprto u arhivu zauvijek. Nope - webmasteri koji posjeduju sadržaj mogu posebno ukloniti sadržaj iz arhive koristeći pristup robots.txt.
Uklonite pojedinačnu stranicu s meta oznakama
Ako imate samo nekoliko pojedinačnih stranica koje želite ukloniti iz rezultata Google pretraživanja, zapravo ne morate koristiti robots.txt pristup uopće, možete jednostavno dodati ispravnu metaoznaku "roboti" na pojedinačne stranice i reći robotima da ne indeksiraju ili ne slijede veze na cijelima stranica.
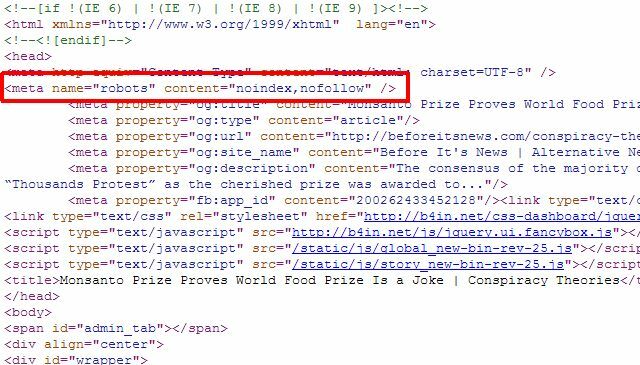
Možete upotrijebiti gornju meta robota da zaustavite robote da indeksiraju stranicu ili možete posebno reći Googleovom robota ne indeksirati, tako da je stranica uklonjena samo iz rezultata Google pretraživanja, a ostali pretraživački roboti još uvijek joj mogu pristupiti sadržaj.
U potpunosti je na vama ovisi o tome kako želite upravljati robotima sa stranicom i hoće li stranica biti navedena ili ne. Za samo nekoliko pojedinačnih stranica možda je to bolji pristup. Da biste uklonili cijeli direktorij sadržaja, prijeđite na metodu robots.txt.
Ideja "uklanjanja" sadržaja
Ova vrsta okreće čitav pojam "brisanja sadržaja s Interneta" u svojoj glavi. Tehnički ako uklonite sve vlastite veze na stranicu na vašoj web lokaciji, a uklonite je iz Google pretraživanja i Internetska arhiva pomoću robots.txt tehnike, stranica je u sve namjere i svrhe "izbrisana" s Interneta. Super je stvar, ako postoje postojeće veze na stranicu, te veze i dalje će raditi, a vi nećete pokrenuti 404 pogreške za te posjetitelje.
To je "nježniji" pristup uklanjanju sadržaja s Interneta bez da se u potpunosti poremeti postojeća veza vaše web stranice na Internetu. Na kraju, kako odlučite upravljati sadržajem koji prikupljaju tražilice i internetska arhiva, ovisi uvijek o vama zapamtite da je unatoč onome što ljudi kažu o životnom vijeku stvari koje se objavljuju na mreži, to u potpunosti unutar vašeg kontrolirati.
Ryan je diplomirao elektrotehniku. Radio je 13 godina u inženjerstvu automatizacije, 5 godina u IT-u, a sada je Apps inženjer. Bivši glavni urednik MakeUseOfa, govorio je na nacionalnim konferencijama o vizualizaciji podataka i bio je prikazan na nacionalnoj televiziji i radiju.